Understanding Generative AI Capabilities in Everyday Image Editing Tasks
Generative AI (GenAI) holds significant promise for automating everyday image editing tasks,
especially following the recent release of GPT-4o on March 25,
2025. However, what subjects do
people most often want edited? What kinds of editing actions do they want to perform (e.g.,
removing or stylizing the subject)? Do people prefer precise edits with predictable outcomes or
highly creative ones? By understanding the characteristics of real-world requests and the
corresponding edits made by freelance photo-editing wizards, can we draw lessons for improving
AI-based editors and determine which types of requests can currently be handled successfully by
AI editors? In this paper, we present a unique study addressing these questions by analyzing 83k
requests from the past 12 years (2013–2025) on the Reddit community, which collected 305k
PSR-wizard edits. According to human ratings, approximately only 33% of requests can be
fulfilled by the best AI editors (including GPT-4o, Gemini-2.0-Flash,
SeedEdit). Interestingly,
AI editors perform worse on low-creativity requests that require precise editing than on more
open-ended tasks. They often struggle to preserve the identity of people and animals, and
frequently make non-requested touch-ups. On the other side of the table, VLM judges (e.g., o1)
perform differently from human judges and may prefer AI edits more than human edits.

tldr
We find that GenAI can satisfy 33.35% of everyday image editing requests, while 66.65% of the requests are
better
handled by human image editors.
Introduction
GenAI for images has gained enormous research interest and created a 2023 market of
$300M, which is estimated to multiply.
Specifically, text-based image editing is an increasingly high-demand task, especially
after the recent GPT-4o and Gemini-2.0-Flash image
generators.
However, four important questions remain open:
Q1: What are the real everyday image editing requests and needs of users?
Q2: According to human judgment, what % of such requests can be satisfied by existing
AIs?
Q3: What are the improvement areas for AI editors compared to human editors?
Q4: Are vision language models (VLMs) judging AI-edited images similarly to human judges?
Q1 and Q2 are unanswered partly because many prior datasets contain made-up requests written by either human
annotators or AIs based on the source image or the (source, target image) pair (see Table Dataset Comparison).
Those request distributions may not reflect the actual editing needs of users as well as the
challenges posed by the real requests, which may have typos, distraction or ambiguity (e.g.,
“I'd love to see how crazy this could get... Thank you in advance!!” in this post;
Figure.1).
On the other hand, some datasets feature images edited by AIs and therefore do not represent the real edits
by advanced
photo editors.
We aim to answer these four questions by analyzing totalimagesize tuples of (source image, text request,
edited image) from the
/r/PhotoshopRequest (PSR) Reddit channel, which is
the largest public online community that shares diverse, everyday image-editing needs with
corresponding edits by PSR wizards (Footnote: Advanced image editors who are granted to handle paid editing
requests in this particular subreddit.).
PSR has 1.7M users and receives an average of 141 new requests per day (our statistics for 2025) with a peak
as high as 226 per day.
To answer Q1, Q2, and Q3, our closed-loop study:
(a) analyzes 305k tuples, i.e., datasetsize unique requests × 3.67
human-edited images per request;
(b) sends all (request, source image) pairs to image-editing models to collect AI edits;
(c) performs a human study over a set of 328 requests (PSR-328) to collect over 4.5k
ratings to compare how 1,644 PSR-wizard edits fare against 2,296 AI edits on the same requests to identify
areas where AIs perform well and fall short.
Our work is the first to compare three state-of-the-art (SOTA): GPT-4o, Gemini-2.0-Flash, and SeedEdit, as
well as 46 other AI models on HuggingFace, for
a total of 49 AI editors.
Furthermore, to address Q4, we compare human ratings against those by 3
SOTA vision-language models (VLMs): GPT-4o, o1, and Gemini-2.0-Flash-Thinking.
Our main findings are as follows:
- 66% of the time, human judges still prefer human, PSR-wizard edits over AI edits.
- While SOTA VLMs are excellent at regular visual tasks, on image-edit judgment, VLMs can
be extremely biased, e.g., o
prefers GPT-4o edits 85% of the
time, which is in contrast to human
judgment.
- AIs often add additional touches, which improve the aesthetic of the image and sometimes win votes even
when such touches are not requested by users.
- GenAI can satisfy 33.35% of the requests, while 66.65% of the existing requests, PSR wizards still
outperform GenAI models.
PSR Dataset Construction
Data Collection
We source our dataset from Reddit's /r/PhotoshopRequest
community (2013–early 2025). Historical data (up to Nov 2022) comes from PushShift, while recent data
(Oct 2024–Feb 2025) is collected daily via a custom crawler, as PushShift lacks data after Nov 2022.
Taxonomy Development
We present a taxonomy capturing the spectrum of image editing requests across three dimensions:
subject, action verb, and creativity level. The subject identifies the element
modified, the action verb specifies the modification, and the creativity level distinguishes routine tasks
from
those allowing multiple, open-ended interpretations.
This framework enables precise analysis of automated image editing tasks and highlights that even routine
edits,
such as object removal, vary significantly depending on whether the
subject is
a person, animal, or object.
While low-creativity tasks often suit standard automation tools, high-creativity tasks (see Figure 2) demand models with greater flexibility.
Subject:
The subject of an image editing request is the specific element being modified—e.g., in a request to remove
a
person, the subject is the person. Subjects may include objects, persons, or the entire image. To
systematically
classify subjects from user instructions, we leverage WordNet's taxonomy.
We first extract subjects from raw instructions, then match each to the nearest synset (semantic category)
in
WordNet's structured lexical database, providing standardized classification and reduced ambiguity.
Action Verb:
Users often describe their editing intentions in vague terms i.e., "Make this look better" instead
of
the more technically precise phrasing such as "Improve the lighting to make the subject stand out".
To
properly categorize user intent, we develop a diverse list of 15 action
verbs that cover various editing
actions.
We find that previous efforts to create action verb taxonomies are tied to specific, low-level tools in
popular image editing
software
tools that do not communicate the high-level user intent and also do not contain specific edit actions like
super-resolution. This limitation motivated us to develop our own taxonomy
to
ensure comprehensive coverage of modern image editing techniques.
To develop our taxonomy, we feed a large random subset of the edit requests into GPT-4o-mini and prompt the model to
summarize common
editing actions.
Additionally, we consult image editing experts in the field to refine our list of actions to accurately
reflect
image-synthesis tasks in computer vision.
Table Action Verbs presents the final list of action verbs.
Creativity Level:
We categorize editing requests into three levels of creativity freedom involved in the editing process and
the
potential variation in the final outcome.
- Low Creativity edits require minimal creative input and produce highly predictable
results
such as "remove a person" or "erase an object".
- Medium Creativity requests allow for some variation but still follow a structured
approach,
for example, "change the background" or "adjust lighting to look cinematic".
- High Creativity requests demand significant creative interpretation and can lead to
widely
different outcomes depending on the editor's vision, for instance, "make this image look
magical"
or "transform this into a fantasy scene".
This creativity classification helps differentiate between objective, technical edits and imaginative,
open-ended transformations, ensuring that automated and human editing processes can be tailored accordingly.
While creativity level is not a traditional dataset metric, we feel that it is an underused tool as a way to
measure model accuracy. When evaluating an image editing model, it is desirable to see pixel-level precision
on
low creativity edits involving real-world objects. However, high creativity edits, such as (f) in Figure 2-f, may not need this level of realistic precision.
Examples
of other levels of creativity can be found in Figure 2 as well.
Dataset Annotation Process
We use GPT-4o-mini and InternVL-2.5-38B
to annotate our
dataset.
GPT-4o-mini generates
taxonomy-related labels, while InternVL-2.5-38B performs image captioning
and keyword extraction.
We prompt InternVL-2.5-38B to
summarize
each image into 36 JSON keys, capturing essential attributes
such
as image type (e.g., photograph or digital art), location, weather conditions, presence of people, and lists
of
objects in the image.
To identify posts unrelated to image editing (e.g., when users post an image seeking proof of authenticity
rather than requesting an edit), we instruct GPT-4o-mini to output a binary
flag, image_editing_relevant, indicating whether the post pertains to image editing.
Extracting Subject and Action Verbs:
We use a zero-shot prompting to extract actions from the request.
GPT-4o-mini is provided with a
list of valid actions, their descriptions,
the
input image, and the user-provided request. The prompt instructs the model to first examine the image,
then
rewrite the instruction in clear and simplified language to eliminate ambiguity, and finally identify
the
subjects of the edits along with the corresponding editing actions.
Mapping Subjects to WordNet:
We map the extracted subjects from the previous stage to WordNet's synsets. Once the subjects are
identified, we
provide GPT-4o-mini with the
image, instruction, and subject, instructing
it to
select the closest WordNet synset based on the given context. Since the generated synset may not always be
valid, we perform a search within the WordNet lexical database using NLTK to find the closest matching
synset
and assign a final synset to the subject.
We use o1-pro to summarize
WordNet
subjects
into higher-level semantic categories and organize them into five main and twelve subcategories. Since the
extracted WordNet synsets
from
the previous step vary in granularity, a reasoning model with long-context capabilities, such as o1-pro, effectively groups these synsets
into structured categories. This
approach results in a more coherent and meaningful subject categories.
Assigning Creativity Levels:
We use few-shot prompting to assign creativity levels. GPT-4o-mini receives
the
original
image and request, along with examples annotated by creativity level, to classify the input accordingly.
Dataset Statistics
Our final dataset consists of 83k posts and 305k edited images, categorized by creativity levels as 56% low,
28% medium, and 16% high. It includes 49,134 unique subjects, predominantly falling under the People and
Related category (53.5%). The primary action requested
predominantly falling under the People and Related category (53.5%). The primary action
requested
by
users is delete (32.9%), typically involving the removal of
individuals
or
visual clutter to enhance aesthetics or professionalism.

Experiment Setup
We conduct a series of studies comparing AI-generated edits with human edits to understand human preferences
and to determine whether automated metrics can serve as reliable proxies for these preferences.
AI editors:
We process each request using three generalist SOTA image editing tools: SeedEdit, Gemini-2.0-Flash, and
GPT-4o .1
For each request, we generate two images using both the original instruction (OI) provided by the user and a
simplified instruction (SI) generated by GPT-4o-mini. Since user-written
instructions often include unnecessary details, we use GPT-4o-mini to refine
them, focusing solely on the core image editing task.
Additionally, for each request, we generate three AI-based image edits using
46 off-the-shelf image editing models hosted on Hugging Face Spaces.
PSR-328 dataset:
Via stratified sampling, we select a random PSR subset that has almost the same amount of images in three
levels of creativity groups (114 low, 101 medium, and 113 high).
On average, each request is edited by an average of five Reddit human editors, resulting in
a total of 1,644 human edits.
We also generate 7 different AI edits per request.
In total, our human study has 10,405 unique 4-tuples (source image, request, AI edit, human edit) for
evaluation—substantially larger than prior studies,
while keeping the human annotation effort manageable.
Human study:
We conduct a comparative evaluation study to assess whether AI-generated edits or those created by Reddit
users better satisfy original image editing requests. To ensure unbiased evaluation, we present randomly
paired AI and human edits in a blind setting to human raters who then vote on which edit best fulfills the
given request.
Automated metrics and VLM judges:
We use two automated evaluation methods to complement our human study: LAION Aesthetic Score
and VLM-as-a-Judge . The Aesthetic Score quantifies visual appeal based on
large-scale human preference data, while VLM-as-a-Judge leverages VLMs to provide evaluative feedback on
images, with reasoning capabilities that articulate specific visual qualities and explain judgments.
Both metrics serve as proxies for human judgment, enabling scalable assessment of AI-generated and
human-edited images.
We use LAION's Aesthetic Score Predictor for calculating aesthetic metrics, and
GPT-4o, o1, and Gemini-2.0-Flash-Thinking
as the VLM models for judgment tasks.
Results
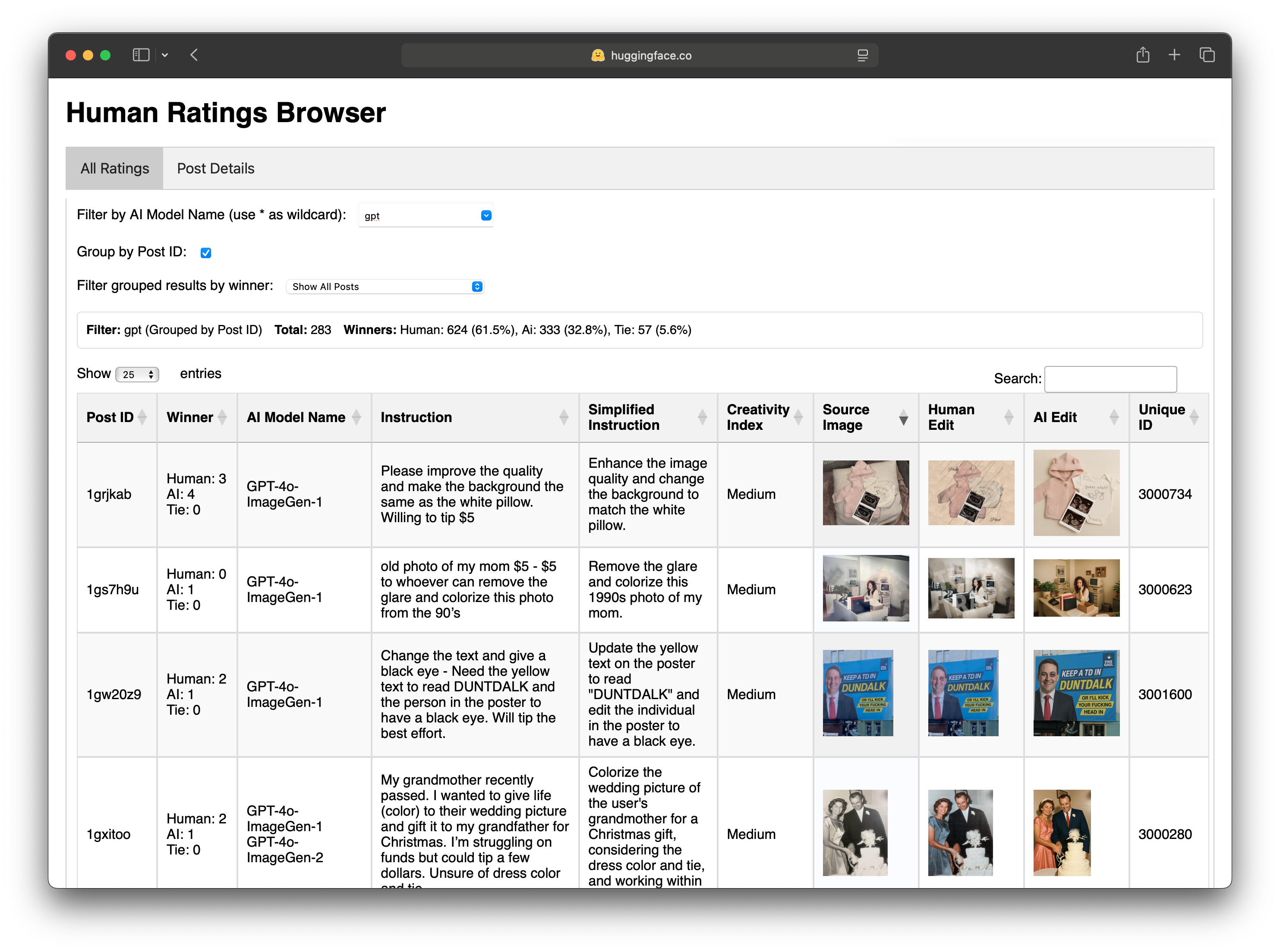
Results Browser
We provide a Hugging Face 🤗 space for the results of our study.
You can filter the results by creativity level, action verb, and model.
Human Edits Are Strongly Preferred by Human Raters
We collect a total of 4,359 human votes from 122 different users, and Table. 3
summarizes the
preferences based on the collected votes.
Human raters prefer human edits in 66.0% of cases, while AI edits are preferred in only 25.8% of cases.
Within the model
groups, the preference for human edits remains consistent across different models, with
preference rates ranging from 53.6% to 73.2% in favor of human edits. SeedEdit achieves the
highest overall preference win rate at 37.8%, followed by GPT-4o, with a win rate of 32.8%.
Breaking down the ratings by creativity still shows a preference for human edits across all three creativity
groups. Although human edits are consistently preferred, the gap between human and AI performance is smaller
for high-creativity
requests (60.9% vs. 30.7%) compared to medium-creativity
(67.6% vs. 25.3%) and low-creativity
requests
(70.1% vs. 21.1%).
We hypothesize that this is because, in high-creativity scenarios, human evaluators tend to prioritize
originality over detail—unlike in low- or medium-creativity requests.
Analyzing model performance across image editing action verbs shows models
struggle with actions like crop and zoom, yet perform competitively with humans on tasks
such as apply and merge.
Furthermore, we conduct a qualitative analysis to identify common
patterns in cases where AI edits either succeed or fail. AI-generated edits typically outperform human
alternatives due to their higher accuracy in reflecting user instructions. This precision in following the
original request accounts for the majority (72%) of AI wins. In contrast, AI edits often lose because they
misunderstand or misinterpret user requests, with comprehension errors representing the most common cause
(43%). Additionally, AI systems frequently introduce unintended changes or artifacts—most notably,
distortions of facial identity—which further diminish their reliability.
A major issue with the current generation of AI image editing models is how they struggle to preserve the
identity of people in an image. This problem is more pronounced in GPT-4o
, as shown in Figure. 3. In this example, using GPT-4o to make successive edits to an
input image of a person results in a final image that loses its similarity to the original person.
VLM-as-a-Judge Is a Poor Proxy for Human Preferences
Automated feedback from a judge model can be used to significantly boost a student model's performance
through processes like reinforcement through AI feedback (RLAIF). To determine the
accuracy of VLM-as-a-Judge feedback, we collect over 10,300 ratings from three separate VLMs acting as
judges between human edits and AI edits.
The results highlight a clear contrast in overall preferences between humans and VLMs, showing that
VLM-as-a-Judge is a poor proxy for human preferences. While humans strongly prefer human-generated edits (as
discussed in the section "Human Edits Are Strongly Preferred by Human Raters"), all three VLMs exhibit mixed
preferences, splitting their selections approximately evenly (around 50%) between human and AI edits.
Additionally, Cohen's κ scores further confirm weak agreement between human
judgments and VLM assessments, with o1
achieving the highest agreement score of κ = 0.22, which nonetheless remains low.
When examining VLM ratings by individual model
groups,
we observe
a clear preference among VLMs for edits produced by SeedEdit and GPT-4o.
Notably, o1 selects edits from GPT-4o 83.9% of the time. Conversely, for
edits generated by Gemini-2.0-Flash
or
Hugging Face models, VLMs generally favor human-made edits. Despite this,
agreement with human judgments remains relatively low, with Cohen's κ ranging from 0.14 to 0.25, which
is near random in some cases.
We analyze a subset of judges' ratings to better understand why their assessments differ from human
judgments. Although VLMs can provide detailed verbal feedback, they often remain blind to critical
details in images and may fail to accurately capture or articulate all differences between image pairs.
Additionally, VLMs occasionally overlook significant aspects, such as changes in characters' identities, and
sometimes even hallucinate nonexistent elements. These issues highlight ongoing challenges in effectively
leveraging VLMs as reliable judges.
AI Models Tend To Improve Aesthetics Even When Not Requested
A common pattern among AI models is their tendency to enhance the aesthetic quality of images, even without
explicit instructions. For instance, they often apply extra touch-ups to human faces, making the skin appear
smoother and more polished. Similarly, the facial features of pets are improved, and even damaged areas,
such as eyes, are restored—even when such changes were never requested.
For example, when instructed simply to remove extraneous elements (Figure
4-a) or
image
background (Figure 4b), SeedEdit and
GPT-4o nonetheless
enhance the dog's overall facial
features beyond the explicit instructions provided by the user.
We report the LAION aesthetic scores for the images in PSR-328 and summarize the results in
(Figure
4-c). The distribution of aesthetic scores confirms that AI models tend to increase
overall image aesthetics. On average, AI-edited images have higher scores ($\mu = 5.56$) compared to
human-edited images ($\mu = 5.18$) and the original source images ($\mu = 5.32$).
Moreover, we compare changes in aesthetic ratings from our human study to examine potential correlations
between AI performance (winning or losing) and human preference. A detailed breakdown of human preferences
based on variations in aesthetic scores is presented in (Figure
4-d).
We observe that AI-generated edits typically achieve higher aesthetic scores than human edits, regardless of
comparison outcome. AI edits become increasingly favored when their aesthetic scores surpass those of human
edits. Nonetheless, human raters generally prefer
human-generated edits overall, indicating that the LAION aesthetic score alone does not fully align with
human preferences.
AI Models Can Successfully Handle One-Third of All Real-World Requests
Different image editing requests necessitate varying types and levels of editing depending on the subject
and required action, ranging from subtle, precise modifications (e.g., ``remove the
quote'' (Figure 2-a)) to complete transformations (e.g.,
``cartoonize this image''
(Figure 2-f). While our results show human edits are generally
preferred, AI models
have shown they can handle a subset of these diverse requests at a competitive rate with human editors. This
capability raises a question: what is the overall percentage of requests that AI models can already handle?
We estimate the overall percentage of real-world image editing requests that AI models can effectively
handle by calculating a weighted average based on the distribution of action verbs in our
dataset. Specifically, we define the effectiveness of AI as the percentage
of tasks where AI-generated edits either outperform (win) or perform competitively (tie) compared to human
edits. For each verb category, we multiply the combined AI win and tie rates by
the proportion that each verb contributes to the overall dataset:
$\sum_{v=1}^{v} D_vAI_v * 100 = 33.35% $
where $D_v$ represents the proportion of dataset requests associated with action verb $v$, and $AI_v$
denotes the combined percentage of AI wins and ties for edits corresponding to verb $v$. Based on this
calculation, we estimate current AI tools effectively handle about one-third of real-world image editing
requests.
Conclusion
In this study, we compared generative AI edits with human edits to understand the gap between the current
capabilities of AI models and actual user needs.
Current AI tools excel in specific tasks such as object removal and outpainting, effectively extending
images and filling in missing details. However,
in real-world scenarios, current generation models can adequately fulfill only about one-third of user
editing requests. Their main constraints stem from their tendency to introduce unintended modifications
beyond the targeted editing region and inadvertently altering essential characteristics, such as the
identity of individuals.
Our dataset annotation and taxonomy generation rely on language models, potentially introducing biases and
inaccuracies. Additionally, certain AI image editing models were inaccessible during our evaluation, leading
to their absence from our human analysis.



